大家好、今天我们一起学习联列表分析,联列表分析是通过频数交叉表来讨论两个或多个变量之间是否存在关联,并且提供了各种双向表检验和相关性测量,基本思路与假设检验基本一致,先建立一个零假设,认为两个变量之间是没有关联的,之后进行卡方检验,计算概率,通过概率是否达到显著性水平来判断,接受或拒绝零假设。
话不多说,直接上操纵。
原始数据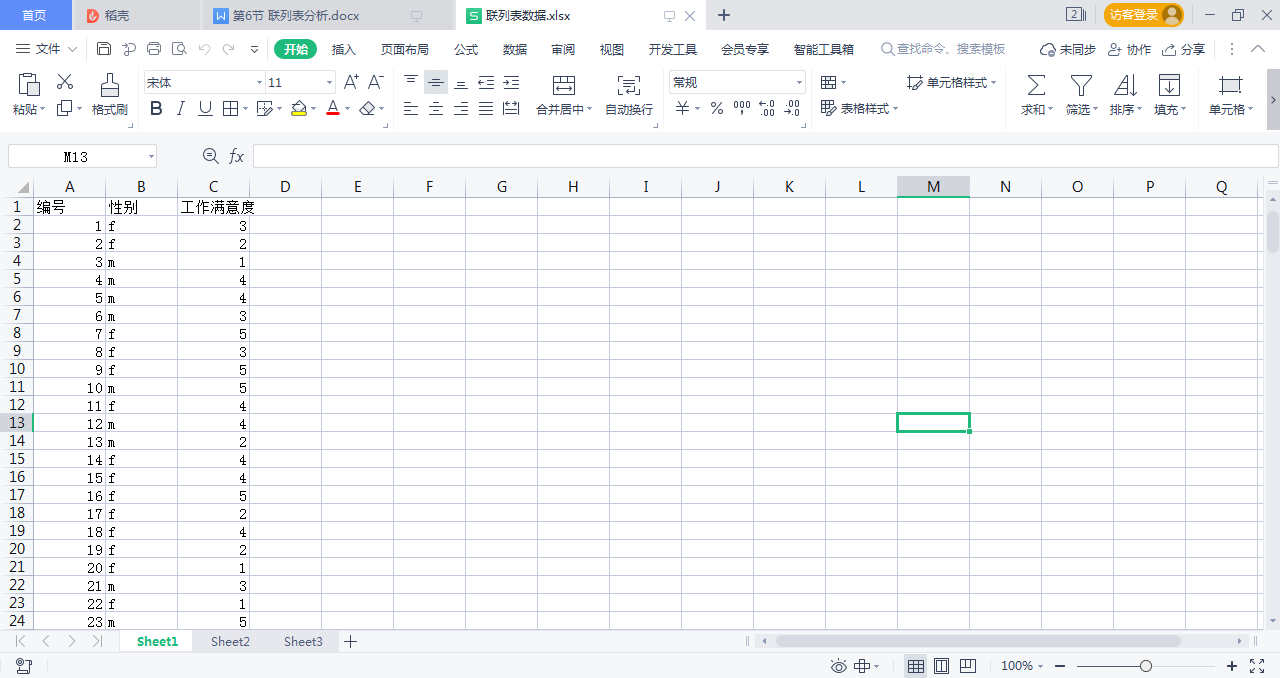
原始数据
操作:
分析→描述统计→交叉表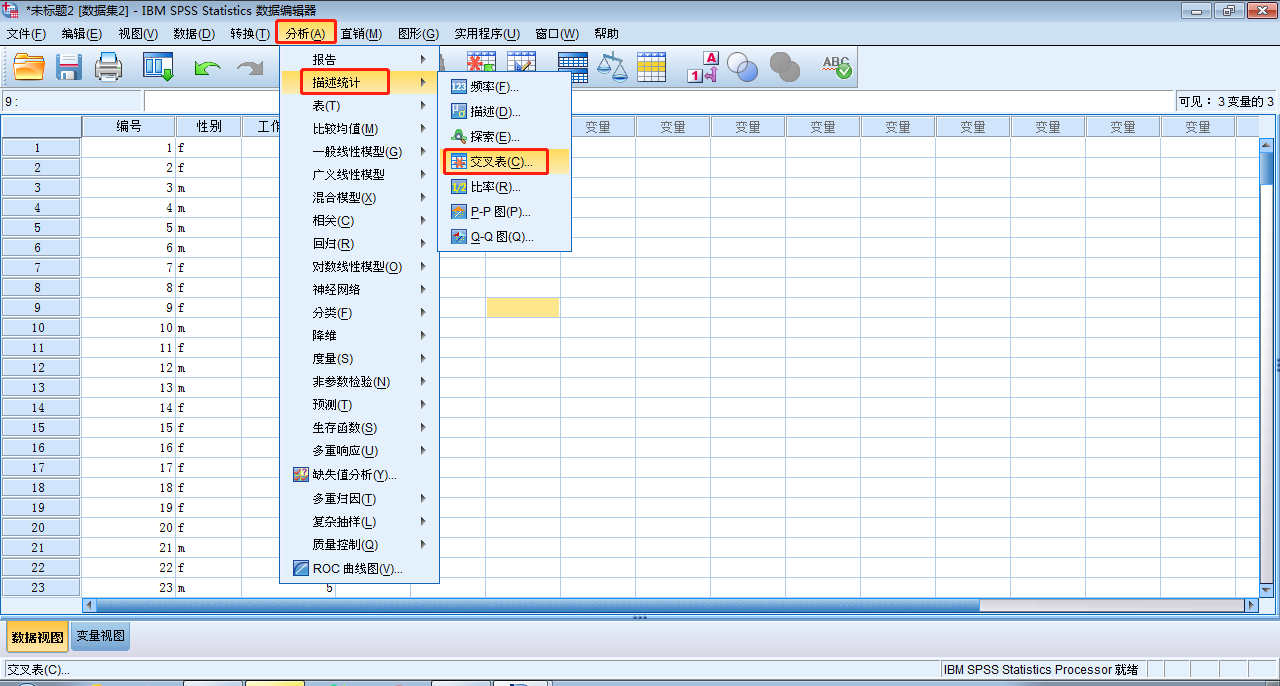
交叉表
精确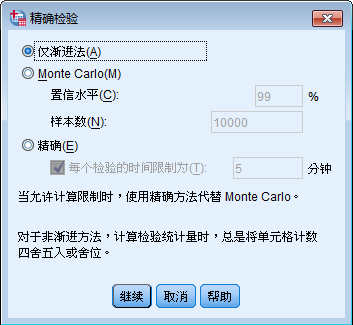
精确
精确检验:
仅渐进法:是基于渐进分布计算的概率值,一般情况下是值小于0.05的认为显著;
Monte Carlo:是根据精确显著水平的无偏估计选择的思想,置信度、样本数;
精确:精确计算概率,当小于0.05的时候认为显著,行变量与列变量相互独立,适用于期望值小于5的情况下使用,所以每个检验的时间限制为5分钟;
统计量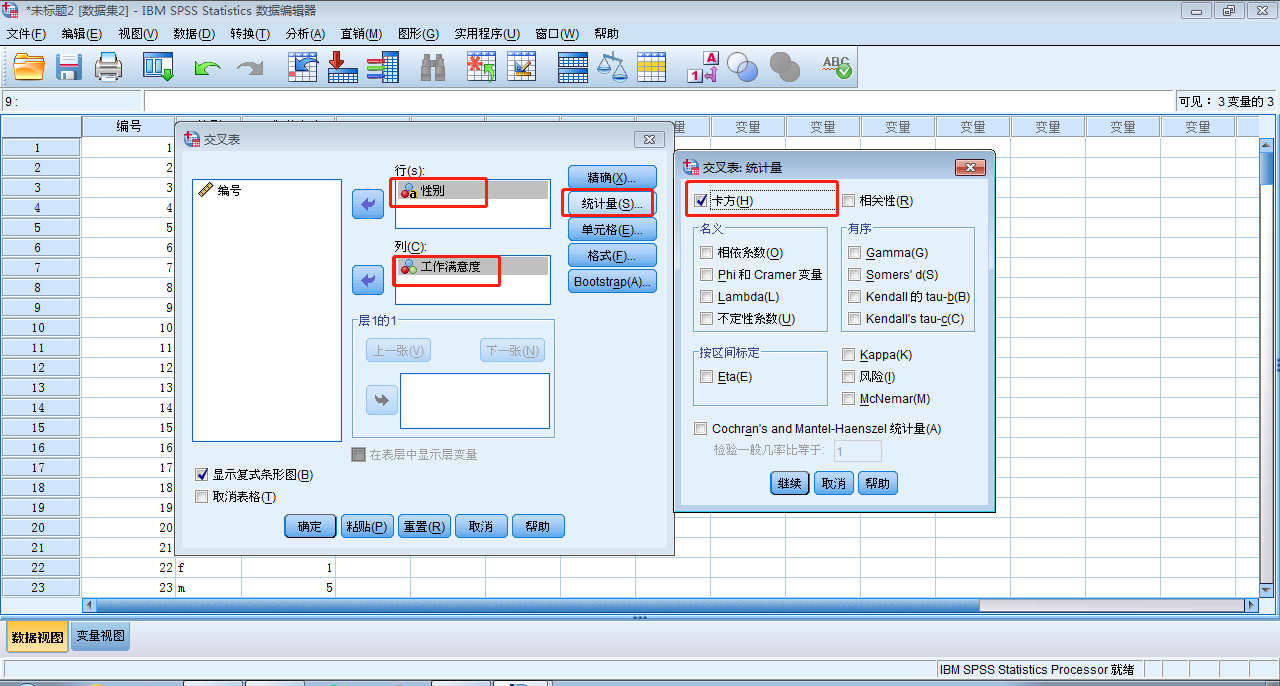
统计量
卡方:卡方检验包括Pearson卡方检验、似然比卡方检验等等,当两个变量都是定量变量时,用来检验行变量和列变量之间是否相关;
相关性:Spearman相关系数用来测量等级系数之间的相关性,当两个变量都是定量变量时,会产生Pearson相关系数;
相依系数:基于卡方检验的相关性测量,取值是在0和1之间,其中0表示行变量和列变量之间不相等,值越趋近于1,表示变量之间的关联性越强;
Phi和Cramer变量:基于卡方统计的相关性测量,取值也是在0和1之间,同上;
Lambda:也是一种相关性的测量,反映的运用自变量的值来预测因变量的值,误差比成比例缩小,取值也是在0和1之间,值越接近1,表示自变量的值能完全预测因变量;
不确定性系数:也是一种相关性测量,表示当一个变量的值用来预测其他变量的值,误差成线性程度,取值也是在0和1之间,值越接近1,表示该变量的值能很好的预测其他变量的程度;
有序
Gamma:测定两个有序变量之间的对称相关性的统计量,取值在-1和1之间,1表示完全正关联,-1表示完全负关联,0表示不相关;
Somers’d:取值在-1和1之间,1表示两个变量之间关联度很高;
有序变量和排序变量的非参数性相关性检验
Kendall的tau-b是将节考虑在内
Kendall的tau-c是未将节考虑在内
按区间标定
Eta:也是关联度的一个统计量,取值是在0和1之间,接近于1表示两个变量高度关联,越接近0表示两个变量关联度很低;
Kappa:用于检验对同一变量两种观测方法是否一致,取值也是在-1和1之间,取值越接近1表明两者趋近一致的概率越大,取值为0表明两者之间没有关联;
风险:用于危险度的分析,表明事情的发生与某因素之间的关联性,当某因素发生的可能性非常小时,使用比数比统计量来测定相对危险度;
McNemar:两个二分变量相关性的非参数检验,用卡方分布检验响应改变,用来检测事件干预导致因变量的变化;
Cochran’s and Mantel-Haenszel统计量:两个二分变量独立性检验的统计量,条件是给另一个或多个分层变量定义协变量的模式,在框中可输入,相对风险检验的0假设值,系统默认为1;
单元格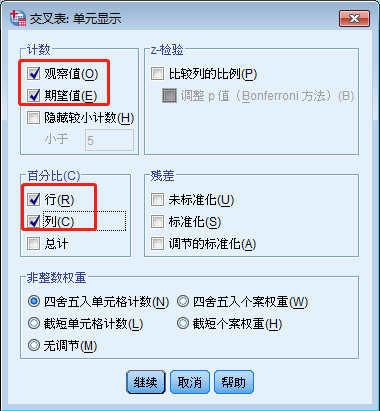
单元格
计数
观察值:显示实际的频数;
期望值:显示期望的频数;
隐藏较小计数:隐藏频数小于指定数(系统默认为5)的计数
Z-检验
比较列的比例:计算列属性的成对比较,并指出给定行数哪些列明显不同;
调整P值:用Bonferroni法进行修正,可以将多个比较后,调整观测值的显著性水平
百分比
行:行百分比;列:列百分比;总计:单元格频数占全部观测量的百分比
残差
未标准化:观察值与期望值之差;
标准化:残差除以其标准差的补给;
调节的标准化:单元格的残差除以其标准误差的估计值;
非整数权重
四舍五入单元格计数:单元格中的个案权重按原样使用,在累计权重中四舍五入;
四舍五入个案权重:对个案权重进行四舍五入;
截短单元格计数:在计算任何统计之前,让权重按原样使用,截短单元格中的累计权重,截取整数部分;
截短个案权重:对个案权重截取整数部分;
无调节:不对单元格进行调节
输出结果
| 案例处理摘要 | ||||||
| 案例 | ||||||
| 有效的 | 缺失 | 合计 | ||||
| N | 百分比 | N | 百分比 | N | 百分比 | |
| 性别 * 工作满意度 | 258 | 100.0% | 0 | 0.0% | 258 | 100.0% |
上表可知,样本数是258个,无缺失值。
| 性别* 工作满意度 交叉制表 | ||||||||
| 工作满意度 | 合计 | |||||||
| 非常不满意 | 不满意 | 一般满意 | 比较满意 | 很满意 | ||||
| 性别 | 女 | 计数 | 30 | 28 | 25 | 30 | 26 | 139 |
| 期望的计数 | 27.5 | 25.9 | 29.6 | 28.0 | 28.0 | 139.0 | ||
| 性别 中的 % | 21.6% | 20.1% | 18.0% | 21.6% | 18.7% | 100.0% | ||
| 工作满意度 中的 % | 58.8% | 58.3% | 45.5% | 57.7% | 50.0% | 53.9% | ||
| 男 | 计数 | 21 | 20 | 30 | 22 | 26 | 119 | |
| 期望的计数 | 23.5 | 22.1 | 25.4 | 24.0 | 24.0 | 119.0 | ||
| 性别 中的 % | 17.6% | 16.8% | 25.2% | 18.5% | 21.8% | 100.0% | ||
| 工作满意度 中的 % | 41.2% | 41.7% | 54.5% | 42.3% | 50.0% | 46.1% | ||
| 合计 | 计数 | 51 | 48 | 55 | 52 | 52 | 258 | |
| 期望的计数 | 51.0 | 48.0 | 55.0 | 52.0 | 52.0 | 258.0 | ||
| 性别 中的 % | 19.8% | 18.6% | 21.3% | 20.2% | 20.2% | 100.0% | ||
| 工作满意度 中的 % | 100.0% | 100.0% | 100.0% | 100.0% | 100.0% | 100.0% |
.
| 卡方检验 | |||
| 值 | df | 渐进 Sig. (双侧) | |
| Pearson 卡方 | 3.075a | 4 | .545 |
| 似然比 | 3.075 | 4 | .545 |
| 有效案例中的 N | 258 | ||
| a. 0 单元格(0.0%) 的期望计数少于 5。最小期望计数为 22.14。 |
上表卡方检验中Pearson卡方的渐进Sig(双侧)的值为0.545大于0.05,接受原假设,说明男女性别对工作满意度无显著性差异。(相反若Sig值小于0.05,说明拒绝原假设,说明有显著性差异。)
柱状图